RAG é a IA buscar trechos de informação relevantes antes de responder, e grounding é ela amarrar a resposta a esses trechos em vez de adivinhar de memória. Os dois termos descrevem o mesmo movimento, visto de ângulos diferentes: RAG (Retrieval-Augmented Generation, ou geração aumentada por recuperação) é o ato de ir buscar o material; grounding (ancoragem em fonte) é o compromisso de não dizer nada que aquele material não sustente. Quando o ChatGPT com busca responde citando de onde tirou a informação, é isso que aconteceu por baixo.
Esse mecanismo é a diferença entre uma IA que responde "do que ela lembra" e uma que responde "do que ela acabou de ler". Para a sua marca, isso importa porque define uma janela de oportunidade que não existia: se o seu conteúdo for fácil de encontrar e claro de ler no momento da pergunta, ele pode virar a fonte que a IA recupera e ancora a resposta, mesmo que o modelo nunca tenha ouvido falar de você no treino. O resto deste texto explica como esse caminho funciona e o que ele cobra do seu site.
Por que um modelo de IA inventa coisas?
Porque, sem recuperar nada, ele responde a partir de probabilidade, não de consulta. Um modelo de linguagem foi treinado para prever a continuação mais provável de um texto. Quando ele responde só com o que memorizou, não está abrindo um arquivo para conferir: está montando a sequência de palavras que mais combina com a pergunta. Na maior parte das vezes acerta. Mas quando não tem a informação com firmeza, preenche a lacuna com algo plausível, e plausível não é o mesmo que verdadeiro. Esse preenchimento confiante e incorreto é o que se chama de alucinação.
O problema fica mais agudo justamente nos casos que interessam a uma marca. Pergunte a um modelo puro o horário, o endereço ou a política de troca de uma empresa específica, e ele tende a inventar um valor verossímil, porque é o tipo de detalhe que muda com o tempo e que ele provavelmente não fixou. O modelo não sabe que não sabe. Ele continua a frase.
A recuperação ataca essa raiz. Em vez de deixar o modelo adivinhar, o sistema busca trechos de texto relevantes primeiro, entrega esses trechos ao modelo junto com a pergunta e instrui: responda com base nisto. Agora ele tem material concreto na frente. A chance de inventar cai, porque ele tem o que copiar em vez de o que imaginar. Não zera, mas cai bastante. É a diferença entre uma prova de memória e uma prova com consulta.
O que é RAG, em uma frase que funciona sozinha?
RAG (Retrieval-Augmented Generation) é a técnica em que a IA busca documentos ou trechos relevantes em uma fonte externa, como a web aberta, e usa esse material recuperado para compor a resposta, em vez de depender apenas do que o modelo memorizou no treino.
A palavra que carrega o peso é "recuperação" (em inglês, retrieval). É a etapa de ir buscar. Antes de RAG, um modelo respondia fechado dentro do próprio conhecimento, congelado na data em que parou de ser treinado. Com RAG, abre-se uma porta para fora: o sistema consulta material atualizado no momento da pergunta e injeta o que encontrou no contexto do modelo. O modelo continua sendo o mesmo motor de previsão de texto, mas agora ele escreve olhando para uma fonte, não só para a memória.
Ferramentas que as pessoas usam todo dia funcionam assim. O ChatGPT com busca ativa, o Perplexity e o Gemini, quando o assunto pede informação recente ou específica, disparam uma busca, leem páginas e respondem a partir delas. Você não precisa montar uma infraestrutura de RAG para se beneficiar: esses produtos já fazem a recuperação por você. O que está em jogo, do lado da sua marca, é se o seu conteúdo é um dos trechos que eles conseguem encontrar e recuperar.
O que é grounding e como ele difere de RAG?
Grounding (ancoragem em fonte) é a prática de fazer o modelo basear cada afirmação da resposta em um trecho concreto que ele recuperou, de modo que a resposta possa ser rastreada de volta até a fonte, em vez de sair da imaginação do modelo.
A relação entre os dois é de meio e fim. RAG é o mecanismo: ir buscar os trechos. Grounding é o resultado que se quer com esse mecanismo: que a resposta fique amarrada aos trechos, sem extrapolar. Dá para fazer RAG mal feito, recuperar trechos e mesmo assim deixar o modelo divagar para além deles. E dá para ter grounding forte, em que o modelo se recusa a afirmar o que a fonte não diz. Por isso vale separar: um é a engrenagem, o outro é a disciplina que se espera dela.
Na prática, grounding aparece de duas formas que você reconhece como usuário. A primeira são as citações: quando a resposta traz links ou referências indicando de onde cada parte veio, é grounding explícito, e é a maior chance de a sua marca virar a fonte nomeada. A segunda é a recusa honesta: um sistema bem ancorado prefere dizer "não encontrei essa informação" a inventar, quando os trechos recuperados não cobrem a pergunta.
Vale uma ressalva honesta, porque grounding não é mágica. Ancorar a resposta em uma fonte só ajuda quando a fonte está certa. Se o trecho recuperado contém uma informação desatualizada sobre a sua empresa, ou vem de uma página que troca o seu nome pelo de um concorrente, o grounding vai repetir o erro com toda a confiança de quem está citando um documento. Recuperar não é o mesmo que verificar. O sistema ancora no que achou, não no que é verdade, e é por isso que a qualidade das fontes que falam de você importa tanto.
Como funciona o caminho da pergunta até a resposta ancorada?
O fluxo, sem o jargão de engenharia, tem três etapas. Entender essa sequência é o que mostra onde o seu site entra na jogada.
-
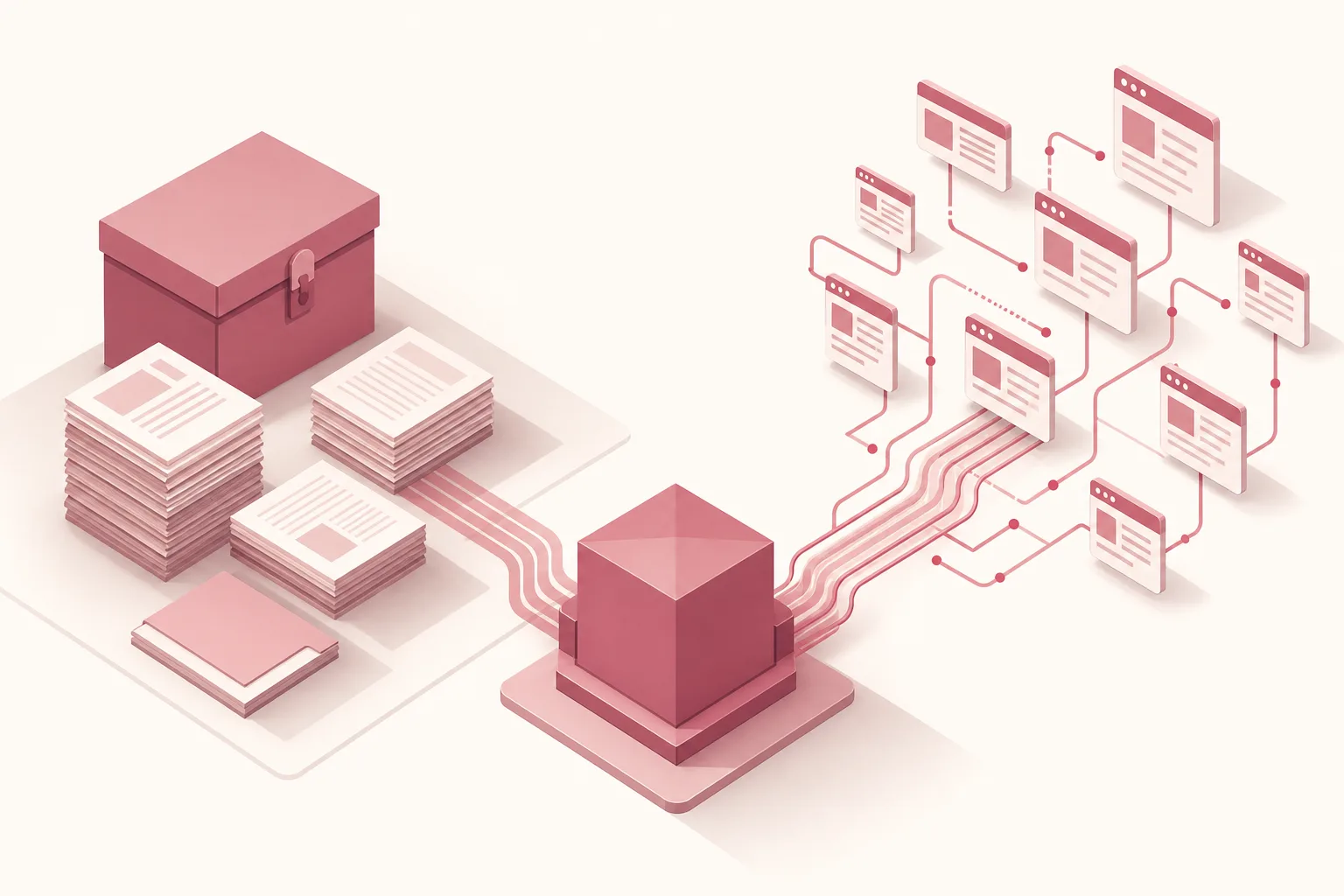
A pergunta vira uma busca. Quando alguém pergunta algo que pede informação específica ou recente, o sistema transforma a pergunta em uma ou mais consultas e vai procurar trechos relevantes, na web aberta ou em uma base de conhecimento. Ele não lê a internet inteira: seleciona um punhado de candidatos que parecem responder ao que foi perguntado.
-
Os trechos são ranqueados por relevância. Entre os candidatos, o sistema escolhe os mais próximos do sentido da pergunta. Essa proximidade é medida comparando representações numéricas de texto, os embeddings (representações numéricas que permitem medir o quanto dois trechos têm significados parecidos). Quanto mais o seu conteúdo casa com a forma como a pergunta foi feita, mais alto ele fica nessa fila. A peça de software que guarda e compara esses vetores costuma ser chamada de banco vetorial.
-
O modelo compõe a resposta ancorado nos trechos. Os trechos selecionados entram no contexto do modelo junto com a pergunta, e ele redige a resposta a partir daquele material, idealmente citando as fontes. É aqui que a sua marca, se foi um dos trechos recuperados, aparece, e às vezes nomeada com link.
O detalhe que muda tudo está na etapa dois. A IA não recupera a melhor empresa, recupera o trecho de texto mais relevante para aquela pergunta. Se o conteúdo sobre a sua marca não estiver claro, não casar com as palavras que as pessoas usam, ou nem chegar a ser lido, ele não entra na fila, e a resposta se ancora em outra fonte. A disputa de RAG é uma disputa por ser o trecho recuperado.
O que esse mecanismo exige do site da sua marca?
Três coisas, na ordem em que elas pesam. Nenhuma é exótica, mas as três precisam estar de pé ao mesmo tempo, porque a recuperação é uma corrente que se rompe no elo mais fraco.
Primeiro, o conteúdo precisa ser rastreável. Se os robôs das IAs não conseguem ler a sua página, por bloqueio, por depender de JavaScript que eles não executam, ou por estar atrás de um login, então não existe trecho para recuperar. Você fica fora da fila antes mesmo de competir. O lado técnico disso, o que liberar e como facilitar a leitura, está detalhado no artigo sobre como deixar o site rastreável por IA.
Segundo, a informação precisa estar clara e direta no texto. Recuperação trabalha com trechos. Uma página em que o dado importante está enterrado numa imagem, espalhado em parágrafos longos ou implícito demais não oferece um trecho limpo para o sistema extrair. Quanto mais a informação estiver dita de forma explícita e autônoma, mais fácil ela vira um pedaço recuperável. O caminho de escrever assim é o que cobrimos em como deixar o conteúdo citável por IA.
Terceiro, o conteúdo precisa casar com a pergunta real. A recuperação compara o sentido da página com o sentido da pergunta. Se as pessoas perguntam "qual a melhor opção de X em Curitiba" e o seu site fala só em jargão interno que ninguém digita, a distância semântica é grande e você não é recuperado. Falar a língua da pergunta, com as palavras que o seu público usa, é o que aproxima a sua página do que foi perguntado. Os embeddings que medem essa proximidade têm o próprio verbete no glossário, para quem quer entender a peça por dentro.
Estar no treino é diferente de ser recuperado na hora?
Sim, e confundir os dois é a origem de boa parte da frustração com visibilidade em IA. São dois caminhos pelos quais a IA conhece a sua marca, com velocidades e alavancas diferentes.
Estar no treino significa que, em algum momento antes da data de corte do modelo, a web falava de você, e o modelo absorveu isso como parte do que aprendeu. Esse conhecimento é difuso, fixo, e só muda quando o modelo passa por um novo ciclo de treinamento, o que leva meses e não vem com promessa de data. É o conhecimento de memória.
Ser recuperado na hora é o caminho de RAG: independe do treino. Mesmo que o modelo nunca tenha visto a sua marca, se a sua página for rastreável e relevante no momento da pergunta, ela pode ser o trecho recuperado e citado em poucos dias. É o conhecimento de consulta, e é muito mais rápido de influenciar.
A boa notícia é que as duas alavancas respondem ao mesmo trabalho. Conteúdo claro, rastreável e consistente melhora a sua chance de ser recuperado agora e de ser bem aprendido no próximo ciclo de treino. O contraste completo entre os dois modos, com a tabela do que você controla em cada um, está no artigo sobre dados de treino x busca na web. E quando a marca some das respostas mesmo com o site no ar, vale entender por que a marca some do ChatGPT antes de mexer no lugar errado.
A leitura prática de tudo isso é direta: a IA cada vez mais responde com o que recupera, não só com o que memoriza, e isso transfere parte do controle de volta para você. O que ela recupera depende de o seu conteúdo ser encontrável, claro e alinhado com a pergunta. Não é um botão que você aperta, é uma condição que você mantém.
É esse o ponto que uma análise técnica do seu site verifica. A Promptis checa se o seu conteúdo está acessível e claro o suficiente para ser recuperado pelas IAs e mostra onde estão os elos fracos da corrente, da rastreabilidade à clareza dos trechos. A primeira análise é grátis e não pede cartão, o que dá para ver se você está apto a ser a fonte que a IA ancora, antes de decidir o que melhorar.